今天要來聊聊的是,有時候資料庫管理系統會使用哈希表 (Hash Table) 來儲存資料。在傳統的資料結構文章中,我們認知的哈希表會長像這樣
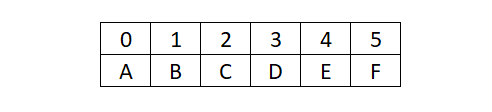
這是最簡單的布置,也就是說,我們在看這個哈希表位置 2 的資料就是 C。但資料怎麼知道要存到哪裡呢? 大部分的時候我們使用的是一個 哈希函數 (Hash Function)
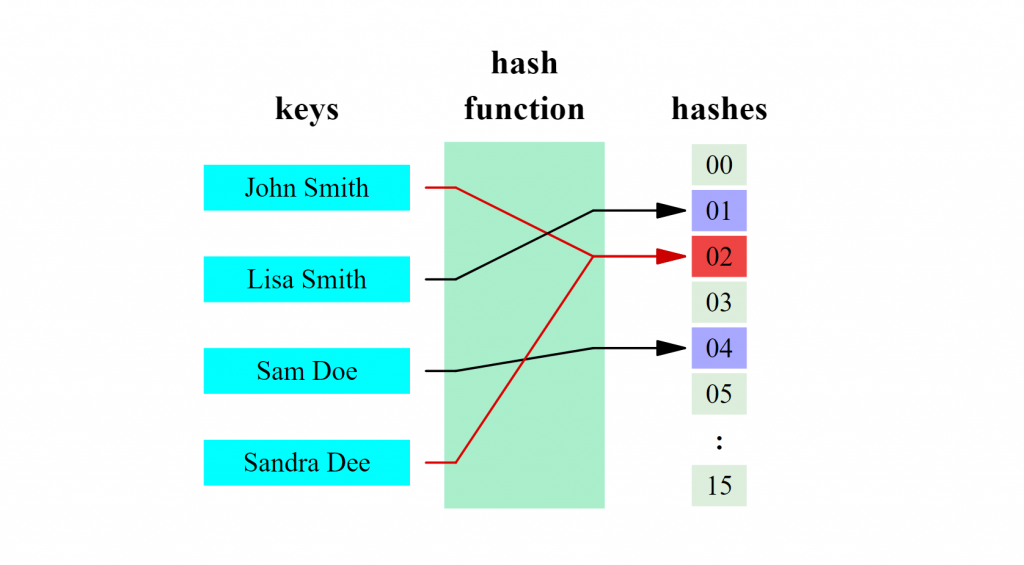
(圖片取自維基百科)
哈希函數的目的在於給任何的數值,我們可以透過這個函數轉換成一個數字,找到相對應的欄位,存取資料。這時候最大的問題是,如果哈希函數把兩個不同的數值轉換成相同的位置,那要怎麼辦。這時候我們就會使用比較進階的哈希表來儲存資料。也就是每個對應到的位置是一個資料鏈,先存的放進去,厚道的往後面鏈結,下面維基百科的圖示中的 John 和 Sandra 就是這樣的例子。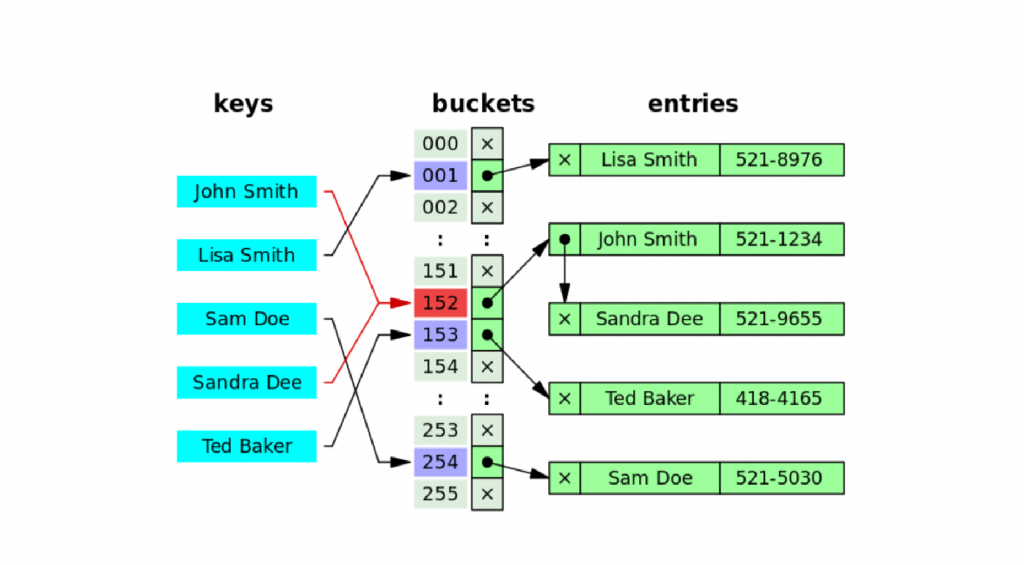
資料庫所使用的哈希表其實大同小異,最大的不同點其實在每個哈希後的位置,都是記憶體中的一個塊 (前天我們有提到)。每個記憶體塊(Block) 中可以存放數筆的紀錄 (Records)。所以即使是哈希到同樣一個位置,我們只要儲存空間夠大,都不會有問題。相同的,如果我們這個資料塊的空間不夠大,我們依然要使用多個記憶體塊來儲存資料。具體一點我們可以把示意圖用下面的方式表示。
記得,資料庫的哈希表一樣會遇到資料儲存時無法將所有的資料放在記憶體或是快取中,所以在下面看到的0、1、2、3 可以想成索引檔之中的索引,分別指向磁碟記憶體裡面的一個位置。在這裡為了簡化人的討論每一個資料的寄一塊就只能存放兩筆資料。
假設現在要插入 M。首先我們先對M哈希,並發現他的索引是1。但是,1 所對應的資料塊已經被兩筆資料填滿了,時候我們就要針對所以你指向的資料塊延伸,指向下一個可以存放m的資料塊,這個概念跟上面傳統的哈希表其實沒有太大的差別。
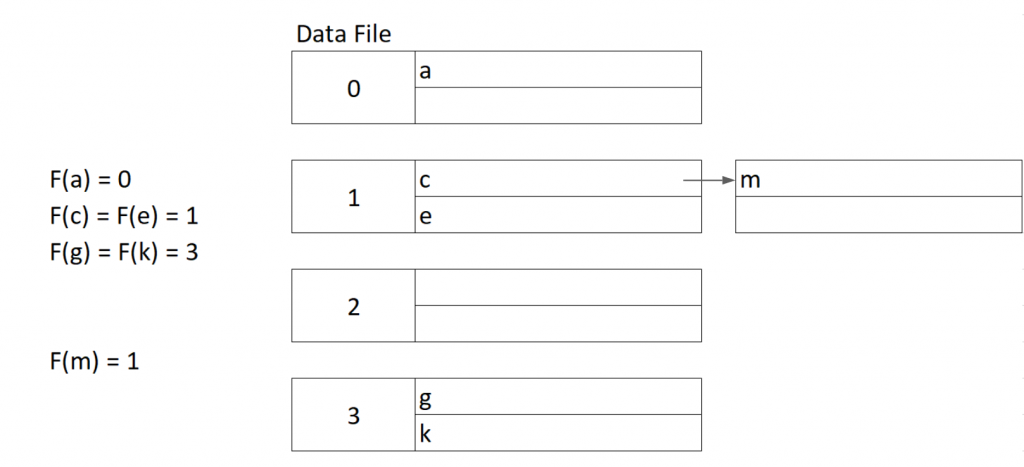
這樣的缺點和傳統的哈希表一樣會使得資料有機會變成一個很長的資料鏈 (Linked List),這樣會讓我們在做查找和儲存的時候變得非常的沒有效率。今天我們要來看哈希表一種減少儲存衝突的方法。
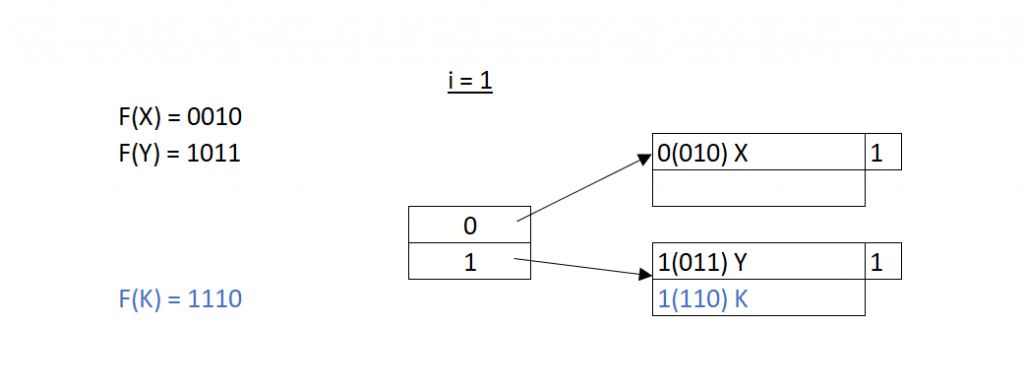
這邊最右邊的就是放在磁碟裡面的記憶塊。中間的 0 和 1 就是放在快取或是記憶體的索引資料。這邊比較有趣的事情是,我們用二進位來表示哈希出來的結果,我們並沒有直接使用這個二進位的數字來找到相對應的儲存位置。這邊我們使用二進位的第一位當作是我們的索引。
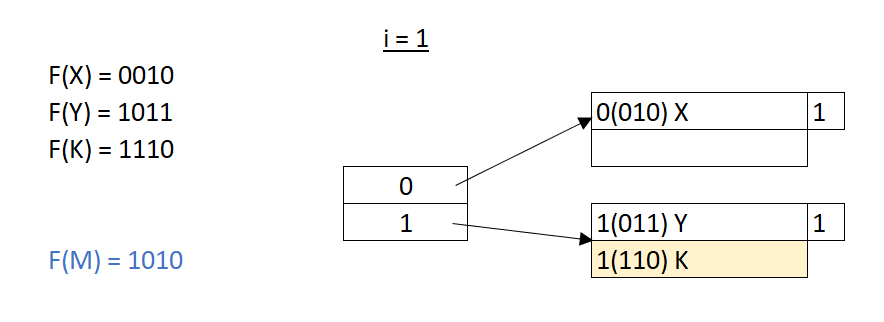
所以當 X 在哈西過後得到的二進位 0010,我們先看這個二進位的第一位數,決定把他哈西在索引為0 指向地的記憶體空間中;同理,我們把 Y 哈西在索引為1的記憶體位置。這時候,我們要插入K,一樣透過哈希所得到的1110,放在記憶體中索引 1 指向的資料塊。
現在的問題是,如果接下來有一個新的 M 值要放進資料庫,而我們哈西過後的結果是是 1010,理論上我們應該要把它哈希在索引 1 指向的資料記憶體位置,但是每一個資料塊中就只能存放兩筆資料,這時候我們就要來擴充哈希表和相對應的索引表。
擴充的方法很簡單,我們把原本只看二進位的第一位數改成看兩個位數,這時候我們的索引表就從兩種可能變成了四種可能 00, 01, 10, 11。
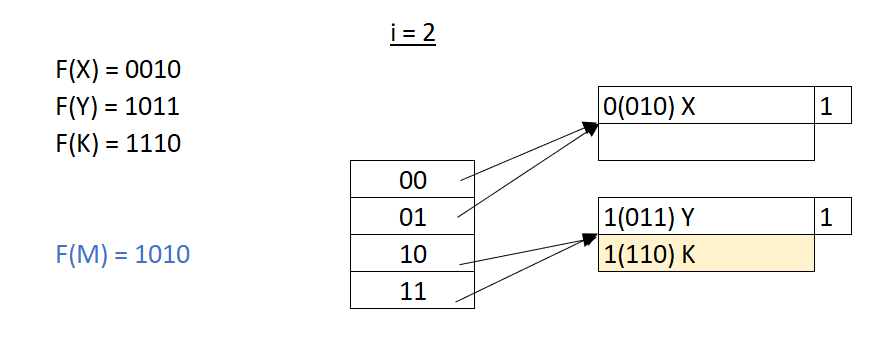
這時候當我們插入M,對應到的索引表就不再是 1 而是 10,相對的,原本 1 指向的記憶體空間變成是 10 和 01;對應到的資料也被放進了兩個不同的資料塊中,讓原本的 Y 和 K 拆成了兩個資料塊,這時候,M就有空間可以放入新的資料塊當中,解決了原本產生衝突的問題,同時我們也避免掉了產生很長的資料鏈的可能性。
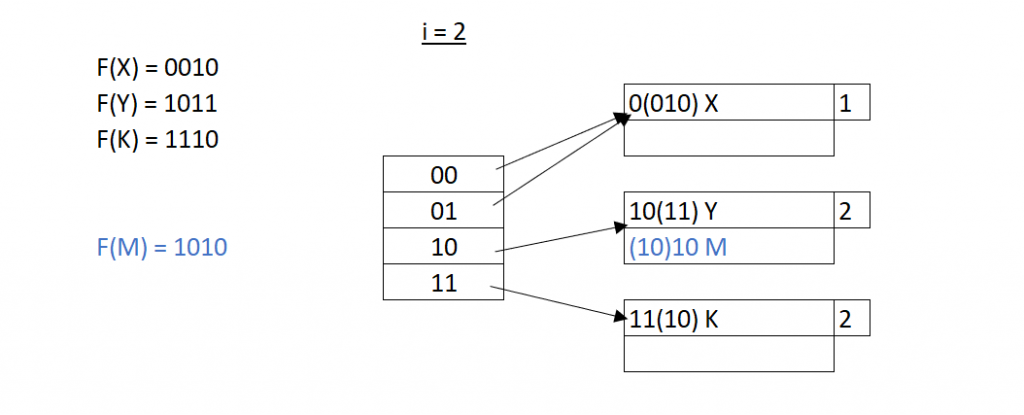
當然這樣的擴充方式並不是完美的,隨著位元數增加,每次需要被迫增加的空間都會加倍。篇幅的關係如果有興趣的讀者可以找稱為 線性哈希 (Linear Hashing) 的方法,比上面的擴充哈希複雜不少,但概念有異曲同工之妙。
明天我們來聊聊資料庫中的交易!

